Object Detection - Considering Current And Future Directions
Object detection is often the first thing that computer vision systems do because it makes it possible to get more information about the object and the scene. Once an object instance, like a face, has been found, more information can be gathered, such as the ability to recognize the particular instance (for example, to recognize the subject's face), to track the object over an image sequence (for example, to track the face in a video), to extract more information about the object (for example, to figure out the subject's gender), and to infer the presence or location of other objects.
Author:Suleman ShahReviewer:Han JuAug 09, 202251 Shares743 Views
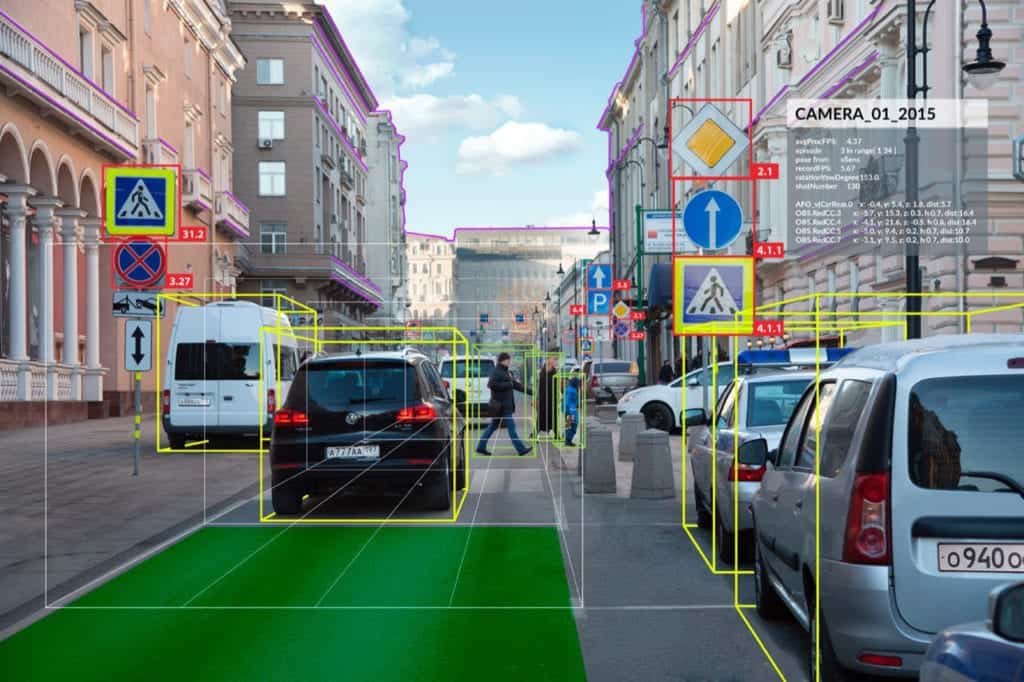
Object detectionis often the first thing that computer vision systems do because it makes it possible to get more information about the object and the scene.
Once an object instance, like a face, has been found, more information can be gathered, such as the ability to recognize the particular instance (for example, to recognize the subject's face), to track the object over an image sequence (for example, to track the face in a video), to extract more information about the object (for example, to figure out the subject's gender), and to infer the presence or location of other objects.
The most common applications for object detection (e.g., autonomous and assisted driving) are human-computer interface (HCI), robotics, consumer electronics, smart phones, security (e.g., recognition, tracking), retrieval (e.g., search engines, photo management), and transportation.
Each of these applications has different needs, such as processing speed (offline, online, or real-time), resistance to occlusion, rotation invariance (for example, rotations in the same plane), and detecting pose change.
A Synopsis Of Object Detection Research
Early object detection studies used template matching and part-based models. Later, statistical classifiers were introduced (Neural Networks, SVM, Adaboost, Bayes, etc.). This original, successful family of object detectors, all based on statistical classifiers, paved the way for much subsequent research in training, evaluation, and classification techniques.
Face detection is the most popular object detection application since it's crucial for human-interfacing systems. Many other detecting issues have been researched.
Most situations involve individuals (e.g., pedestrians), bodily parts (e.g., faces, hands, and eyes), vehicles (e.g., cars and airplanes), and animals. Most object detection systems use the sliding window method to find items at different scales and locations.
This search uses a classifier, the detector's core, to determine if an image patch represents an item. To be certain that the classifier works at a specified scale and patch size, downscaled versions of the input image are used to classify all potential patches of the given size.
Sliding windows have three possibilities. The first is based on bag-of-words, a method used to verify the presence of an object by iteratively refining the image region containing the object. The second one samples patches and iteratively looks for potential object locations.
These two techniques decrease the number of image patches to classify, avoiding an exhaustive search. The third approach matches key-points to be detected. These approaches can't always discover all object instances.
Video unavailable
This video is unavailable
Object Detection Approaches
There are five different types of object detection methods, each with advantages and disadvantages. Some are more robust than others, some can be used in real-time systems, some can handle more classes, etc.
Coarse-To-Fine And Boosted Classifiers
The boosted cascade classifier by Viola and Jones is the most well-known piece of work in this category. It uses a series of tests and filters to get rid of picture patches that don't match the object.
Cascade methods are often used with boosted classifiers for two main reasons: (i) boosting creates an additive classifier, which makes it easy to control the complexity of each stage of the cascade, and (ii) boosting can also be used to select features during training, which makes it possible to use large families of features that have been parameterized.
When efficiency is a crucial need, a coarse-to-fine cascade classifier is typically the first type to take into account.
Dictionary Based
The Bag of Words approach is the best illustration of this type. Although the main goal of this method is to identify a single object in each image, it is also possible to identify additional things after an object has been identified. This method has two problems: it can't handle situations where two copies of the same object are close together, and it may not be able to find the exact location of the object.
Deformable Part-Based Model
This method takes into account the relative positions of the object and part models. It is generally more reliable than other methods, although it takes a while and cannot pick up items that occur on a small scale. Although it can be traced back to deformable models, effective techniques are more recent.
Works by Felzenszwalb et al., Yan et al., and Divvala et al., among others, are important because they use a coarse-to-fine cascade model to evaluate deformable part-based models quickly and effectively.
Deep Learning
Convolutional neural networks are the foundation of one of the earliest effective techniques in this family. The main distinction between this strategy and the ones mentioned before is that in this approach, the feature representation is learnt rather than created by the user. But this method has the drawback that it takes a lot of training examples to teach the classifier what to do.

Object Detection and Recogition
Trainable Image Processing Architectures
In these designs, the parameters of preset operators and their combinations are learned, occasionally taking an amorphous concept of fitness into account. These architectures are general-purpose, so they can be used to create a number of modules for a bigger system (e.g., object recognition, key point detectors, and object detection modules of a robot vision system). Examples include Cartesian Genetic Programming and trainable COSFIRE filters (CGP).
Current Research Problems
Multi-Class
Multiple object classes must be detected for many applications. Processing speed and the types of classes the system can handle without accuracy loss become crucial factors when a high number of classes are being recognized.
Efficiency has been addressed by, among other things, using the same representation for various object classes and using multi-class classifiers that are particularly designed to identify numerous classes. One of the few efforts on very large-scale multi-class object detection that is currently available, Dean et al., took into account 100,000 object classes.
Multi-View, Multi-Pose, Multi-Resolution
With the exception of deformable part-based models, which can handle some posture changes, the majority of approaches used in practice have been intended to detect a single object class under a single view and therefore cannot handle multiple views or huge pose variations. According to several studies, object detection can be improved upon by learning subclasses or by classifying views and poses as separate classes. In addition, models with many poses and resolutions have been generated.
Efficiency And Computational Power
Any object detecting system should take efficiency into consideration. As previously noted, a coarse-to-fine classifier is typically the first type of classifier to take into account when efficiency is a critical need. Other methods include reducing the number of image patches that are used to classify and recognizing more than one class.
Efficiency does not always equate to real-time performance, and while efforts by Felzenszwalb et al. are reliable and efficient, they are too slow to solve real-time challenges. But some techniques, like deep learning, can work in real time if you use specialized hardware, like a GPU.
Contextual Information And Temporal Features
Speed and robustness can be increased by incorporating contextual data (such as information about the type of scene or the presence of other objects), although it is still unclear "when and how" to do this (before, during, or after the detection).
Use of spatiotemporal context, spatial structure among visual words, and semantic information seeking to map semantically linked aspects to visual words are a few of the ways that have been suggested, among many others. Most techniques focus on finding objects in a single frame, but it can be helpful to look at how they change over time.
In the following, we will discuss issues that, in our opinion, have either not been addressed at all or have been treated only in part, and which we believe could be fascinating and significant research paths.

Open-World Learning And Active Vision
After the "primary" class has been learnt, the ability to gradually learn, detect new classes, or learn to distinguish between subclasses is a significant challenge. If this can be accomplished unsupervised, it will be much easier to generate new classifiers based on current ones, which will significantly reduce the time spent learning new object classes.
Keep in mind that as people constantly create new things and alter fashion, etc., detection systems will need to be updated on a regular basis by either adding new classes or modifying existing ones.
These concerns have been addressed in some recent publications, primarily using deep learning and transfer learning techniques. Open-world learning is especially crucial in robot applications where active vision techniques can help with detection and learning.
Object-Part Relation
Should we detect the object or the pieces first during the detection process? There is no obvious solution to this fundamental conundrum. Most likely, it will be necessary to look for both the object and the pieces at the same time, with each search giving information to the other.
It's still unclear how to accomplish this, although it's probably related to using context information. Furthermore, interactions across several hierarchies develop when the object portion can also be broken down into smaller sections, making it generally unclear what should be done first.
Multi-Modal Detection
In the past few years, there has been some advancement in the utilization of new sensing modalities, particularly thermal and depth cameras.
Thermal images, however, and to a lesser extent, depth images, are processed using the same techniques as visual images. While separating the foreground from the background is made easier by using thermal pictures, this technique can only be used with infrared-emitting items (e.g., mammals, heating, etc.).
It is simple to split the objects using depth photos, but no general techniques for identifying particular classes have been presented, and possibly higher resolution depth images are needed.
Depth and thermal cameras don't seem to be good enough for object detection with the resolution they have now, but as sensor technologyimproves, more improvements are likely.
People Also Ask
What Are The Methods For Object Detection?
Convolutional neural networks (R-CNN, Region-Based Convolutional Neural Networks), Fast R-CNN, and YOLO (You Only Look Once) are popular object detection techniques. YOLO belongs to the single-shot detector family, whereas the R-CNNs are members of the R-CNN family.
What Is Object Detection In Python?
This technology has the ability to recognize and track things in pictures and videos. Object detection, commonly referred to as object recognition, has several uses, including security systems, self-driving cars, pedestrian counts, vehicle recognition, and much more.
What Is Object Detection In Convolutional Neural Networks?
Use a bounding box to find the presence of items, and look for the classes of those objects. There are two primary categories of object recognition neural network architectures that have been developed so far: Single-Stage vs. Multi-Stage Detectors Multiple-Stage Detectors.
Which Dataset Is Best For Object Detection?
A large-scale object detection dataset called MS COCO takes three basic scene recognition analysis challenges into consideration. Identifying non-iconic scenes (or non-canonical views) for items, in addition to correcting the 2D localization of such objects.
Conclusion
The majority of computer vision systems and robot vision systems depend heavily on object detection. We are still a long way from reaching human-level performance, especially when it comes to learning in the open world. This is true even though many consumer electronics now use some existing techniques (like face detection for auto-focus in smartphones) or have them built into technologies that help drivers.
It should be emphasized that, despite its potential value, object detection has not been applied frequently in many fields. As mobile robots and generally self-driving machines like quad-copters, drones, and soon service robots, are used more and more, object detection systems are becoming more and more important.
Finally, we need to keep in mind that object detection systems will be required for nanorobots or robots that explore previously unexplored regions, such as the deep ocean or other planets, and that these systems will need to pick up new item classes when they are encountered. A real-time, open-world learning capability will be essential under these circumstances.

Suleman Shah
Author
Suleman Shah is a researcher and freelance writer. As a researcher, he has worked with MNS University of Agriculture, Multan (Pakistan) and Texas A & M University (USA). He regularly writes science articles and blogs for science news website immersse.com and open access publishers OA Publishing London and Scientific Times. He loves to keep himself updated on scientific developments and convert these developments into everyday language to update the readers about the developments in the scientific era. His primary research focus is Plant sciences, and he contributed to this field by publishing his research in scientific journals and presenting his work at many Conferences.
Shah graduated from the University of Agriculture Faisalabad (Pakistan) and started his professional carrier with Jaffer Agro Services and later with the Agriculture Department of the Government of Pakistan. His research interest compelled and attracted him to proceed with his carrier in Plant sciences research. So, he started his Ph.D. in Soil Science at MNS University of Agriculture Multan (Pakistan). Later, he started working as a visiting scholar with Texas A&M University (USA).
Shah’s experience with big Open Excess publishers like Springers, Frontiers, MDPI, etc., testified to his belief in Open Access as a barrier-removing mechanism between researchers and the readers of their research. Shah believes that Open Access is revolutionizing the publication process and benefitting research in all fields.

Han Ju
Reviewer
Hello! I'm Han Ju, the heart behind World Wide Journals. My life is a unique tapestry woven from the threads of news, spirituality, and science, enriched by melodies from my guitar. Raised amidst tales of the ancient and the arcane, I developed a keen eye for the stories that truly matter. Through my work, I seek to bridge the seen with the unseen, marrying the rigor of science with the depth of spirituality.
Each article at World Wide Journals is a piece of this ongoing quest, blending analysis with personal reflection. Whether exploring quantum frontiers or strumming chords under the stars, my aim is to inspire and provoke thought, inviting you into a world where every discovery is a note in the grand symphony of existence.
Welcome aboard this journey of insight and exploration, where curiosity leads and music guides.
Latest Articles
Popular Articles